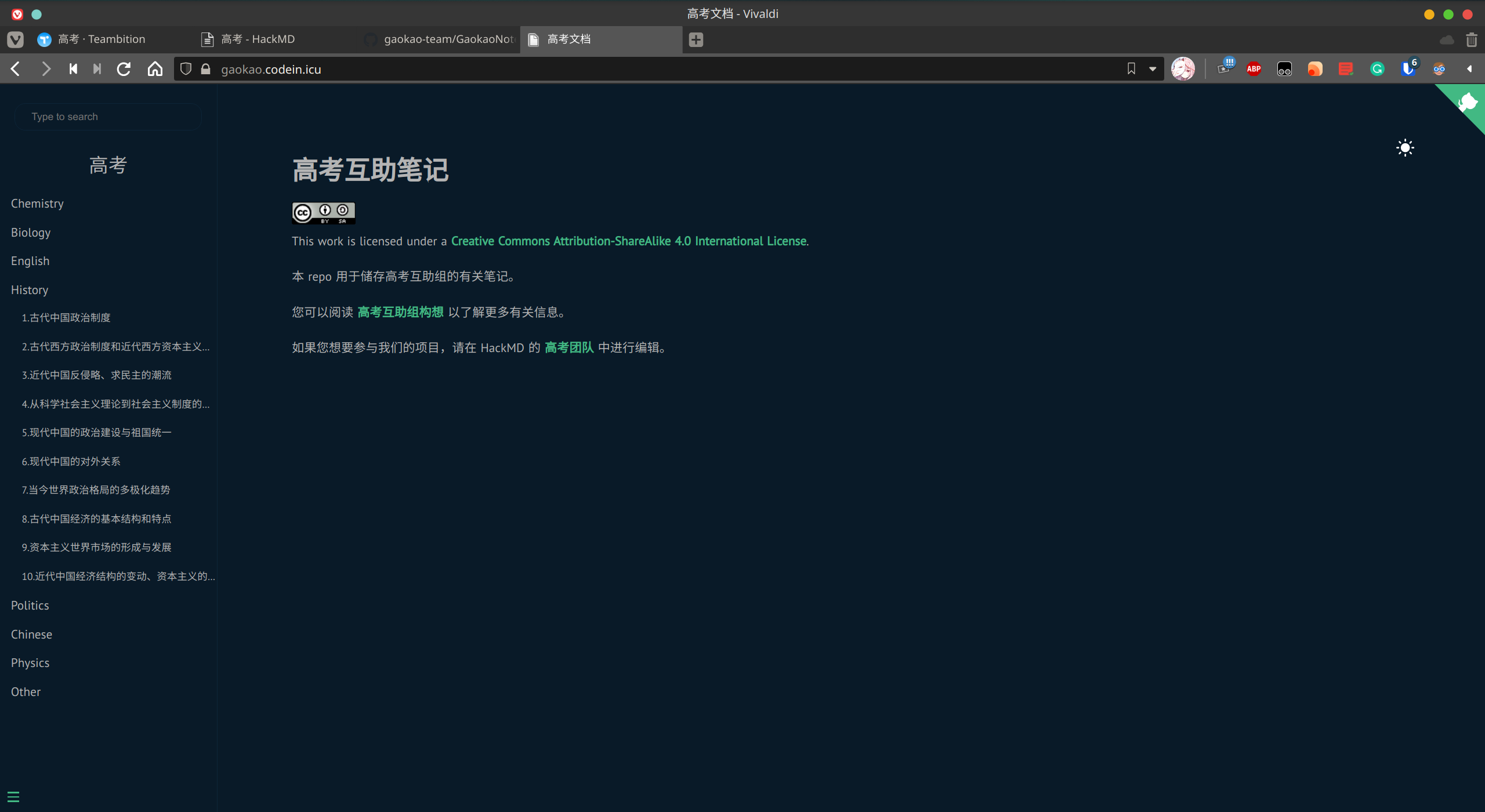
Recently, Gaokao Team has been running for a couple of days and produced an amount of work.

Our geek-style document tool HackMD is satisfying in many aspects, including the well-performed markdown editor and the sync-with-Github utility.
However, there are still two drawbacks:
- It is not accessible in China. Due to the special network condition in China, HackMD, as a foreign service whose servers are located outside China, is blocked by GFW. Although editors can use it with proxies, normal readers may bother to browse.
- Fulltext search is not supported. This utility is frequently needed and we have to import the files to a local editor to perform it, which is not handy enough.
As a consequence, I spent an afternoon setting up Gaokao-Docs to solve these two problems.
Framework
I finally picked up Docsify for these reasons:
- It’s easy to set up. Only a single file is required and it directly renders markdown files with no additional work needed.
- Supporting fulltext search.
- Fully static and hence can be hosted on Github Pages or something like that.
- PWA support, which may better the browsing experience in China.
The biggest drawback is that MathJax is not officially supported. Only a KaTeX plugin can be found but the mhchem package is not included. As I cannot grapple with it, I finally gave up rendering math formulas.
I have no choice but to believe that all my readers have the power to render LaTeX formulas with their bare eyes.
Deploying
Deploying is easy to some extent.
Create index.html in your root directory and here it is.
Some essential configurations are done:
- Changed theme to support dark mode.
- Added full-text search plugin.
- Added TOC collapse plugin.
- enabled PWA.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
|
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>高考文档</title>
<meta http-equiv="X-UA-Compatible" content="IE=edge,chrome=1" />
<meta name="description" content="Description">
<meta name="viewport" content="width=device-width, initial-scale=1.0, minimum-scale=1.0">
<link rel="stylesheet" href="//cdn.jsdelivr.net/npm/docsify-darklight-theme@latest/dist/style.min.css" title="docsify-darklight-theme" type="text/css"/>
</head>
<body>
<div id="app"></div>
<script>
window.$docsify = {
name: '高考',
repo: 'gaokao-team/GaokaoNote',
loadSidebar: true,
subMaxLevel: 2,
search: 'auto',
}
</script>
<!-- Docsify v4 -->
<script src="//cdn.jsdelivr.net/npm/docsify@4"></script>
<script src="//cdn.jsdelivr.net/npm/docsify-darklight-theme@latest/dist/index.min.js" type="text/javascript"></script>
<script src="//cdn.jsdelivr.net/npm/docsify/lib/plugins/search.min.js"></script>
<script src="https://cdn.jsdelivr.net/npm/docsify-sidebar-collapse/dist/docsify-sidebar-collapse.min.js"></script>
<script>
if (typeof navigator.serviceWorker !== 'undefined') {
navigator.serviceWorker.register('sw.js')
}
</script>
</body>
</html>
|
Docsify can’t automatically fetch the files in subfolders.
Some specific tools are needed to do this work, but the existing tools all use filenames to generate a catalog while I want the title of the articles to be displayed.
So I wrote a piece of C++ code to help me with this staff.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
|
#include <iostream>
#include <fstream>
#include <string>
#include <filesystem>
using std::endl;
using std::ofstream;
using std::ifstream;
using std::string;
using std::filesystem::directory_iterator;
int main()
{
string path = std::filesystem::current_path();
ofstream output;
output.open(path + "/_sidebar.md");
for (const auto & sub : directory_iterator(path))
{
if (!sub.is_directory()) continue;
if (sub.path().filename() == ".git" || sub.path().filename() == ".vscode") continue;
output << " - " << sub.path().filename().generic_string() << endl;
for (const auto &file : directory_iterator(sub.path()))
{
if(file.path().extension() == ".md")
{
ifstream reader;
reader.open(file.path());
string now;
do { reader >> now; }while(now != "#");
getline(reader,now);
while(now.back() == ' ') now.pop_back();
while(now.front() == ' ') now.erase(now.begin());
//now is the title of the file
output << " - [" << now << "](/" << sub.path().filename().generic_string()
<< '/' << file.path().filename().generic_string() << ')' << endl;
reader.close();
}
}
}
return 0;
}
|
Done