记录一下 MIT 6.S081 的学习过程。主要是写 Lab 的经历吧,知识相关的笔记就不写了。
6.S081 Fall 2021
第一部分,包含 LEC1-9 的内容。
LEC 1
第一节课就简单介绍了一下课程的目的,然后看了一些 system call 的例子。
Lab 就是搭好 xv6 的环境。跑在 QEMU 里。
Windows 下建议使用 WSL,安装 Ubuntu 20.04.
1
2
|
$ sudo apt-get update && sudo apt-get upgrade
$ sudo apt-get install git build-essential gdb-multiarch qemu-system-misc gcc-riscv64-linux-gnu binutils-riscv64-linux-gnu
|
然后把 xv6 拉下来。
1
2
3
4
5
6
7
|
$ git clone git://g.csail.mit.edu/xv6-labs-2021
Cloning into 'xv6-labs-2021'...
...
$ cd xv6-labs-2021
$ git checkout util
Branch 'util' set up to track remote branch 'util' from 'origin'.
Switched to a new branch 'util'
|
(参考 https://pdos.csail.mit.edu/6.828/2021/tools.html https://pdos.csail.mit.edu/6.828/2021/labs/util.html)
然后可以跑一下编译。编译完了之后就进入了 xv6 的 shell 中。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
|
$ make qemu
riscv64-unknown-elf-gcc -c -o kernel/entry.o kernel/entry.S
riscv64-unknown-elf-gcc -Wall -Werror -O -fno-omit-frame-pointer -ggdb -DSOL_UTIL -MD -mcmodel=medany -ffreestanding -fno-common -nostdlib -mno-relax -I. -fno-stack-protector -fno-pie -no-pie -c -o kernel/start.o kernel/start.c
...
riscv64-unknown-elf-ld -z max-page-size=4096 -N -e main -Ttext 0 -o user/_zombie user/zombie.o user/ulib.o user/usys.o user/printf.o user/umalloc.o
riscv64-unknown-elf-objdump -S user/_zombie > user/zombie.asm
riscv64-unknown-elf-objdump -t user/_zombie | sed '1,/SYMBOL TABLE/d; s/ .* / /; /^$/d' > user/zombie.sym
mkfs/mkfs fs.img README user/xargstest.sh user/_cat user/_echo user/_forktest user/_grep user/_init user/_kill user/_ln user/_ls user/_mkdir user/_rm user/_sh user/_stressfs user/_usertests user/_grind user/_wc user/_zombie
nmeta 46 (boot, super, log blocks 30 inode blocks 13, bitmap blocks 1) blocks 954 total 1000
balloc: first 591 blocks have been allocated
balloc: write bitmap block at sector 45
qemu-system-riscv64 -machine virt -bios none -kernel kernel/kernel -m 128M -smp 3 -nographic -drive file=fs.img,if=none,format=raw,id=x0 -device virtio-blk-device,drive=x0,bus=virtio-mmio-bus.0
xv6 kernel is booting
hart 2 starting
hart 1 starting
init: starting sh
$
|
按下 Ctrl-a x 即可退出。
运行 make grade 即可评测 solutions.
Lab
阅读 xv6 book 的第一章,然后完成本节的 Lab.
fork 和 exec 分离后,可以在 fork 之后进行 IO 重定向再执行新的程序,比较灵活。
fork 创建的子进程虽然拷贝了一份 file descriptor table,但文件指针的偏移是父亲共享的。hmm.
dup system call 也可以拷贝一个已经存在的 file descriptor,共享偏移。
一个例子是 ls existing-file non-existing-file > tmp1 2>&1,其中 2>&1 让 shell 复制一个 1 的 file descriptor 作为 2,那么 stderr 就会和 stdout 一起输出到 tmp1 文件中。
偏移量共享机制有助于保持输出的连贯性。
看完就可以做 Lab 了。
sleep(easy)
实现 sleep 程序。
直接调用 sleep 的 system call 就可以了。
写完之后执行
即可评测。
pingpong(easy)
父进程给子进程发一个 ping,子进程收到后输出 ping,然后回传一个收到标志,父进程随后输出 pong.
用一个管道就可以了。
primes(moderate)/(hard)
上难度力。
用管道写一个异步版本的素数筛??
我一开始以为是投放数字,每个进程拿到数字,然后判断是不是素数。不过这个显然远远劣于各种线性筛。
看了相关材料才知道是用埃氏筛啊,每个进程负责筛掉某些倍数。
每个进程从父亲拿到的第一个数字就是素数,然后用这个素数筛接下来的数。筛完之后按顺序给子进程继续筛。
很炫酷。
这个要写出真正的异步效果还是比较困难的。很容易写出同步版本。
- 注意关闭各种文件指针,不然很容易占用过多而无法执行下去。
- 注意等待子程序运行完成。
- 可以用 uint8 来减少一些占用。当然其实没啥必要。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
#include "kernel/types.h"
#include "user/user.h"
void handle(int IN) {
uint8 prime;
if (read(IN, &prime, sizeof(prime)) <= 0) {
close(IN);
exit(0);
}
fprintf(1, "prime %d\n", prime);
int p[2];
pipe(p);
if (fork()) {
close(p[0]);
uint8 x;
while (read(IN, &x, sizeof(x)))
if (x % prime)
write(p[1], &x, sizeof(x));
close(IN);
close(p[1]);
wait(0);
exit(0);
} else {
close(p[1]);
close(IN);
handle(p[0]);
}
}
int main() {
int p[2];
pipe(p);
for (uint8 i = 2; i <= 35; ++i)
write(p[1], &i, sizeof(i));
close(p[1]);
handle(p[0]);
exit(0);
}
|
find(moderate)
写一个非常简陋的 find.
其实对着 ls 一顿猛抄就可以了,然后加上简单的递归。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
#include "kernel/types.h"
#include "kernel/fs.h"
#include "kernel/stat.h"
#include "user/user.h"
char *get_name(char *s) {
char *p = s;
while (*p)
++p;
while (p >= s && *p != '/')
--p;
return p + 1;
}
void find(char *path, char *name) {
// printf("find in path %s, name %s\n", path, name);
int fd;
if ((fd = open(path, 0)) < 0) {
printf("find: cannot open %s\n", path);
return;
}
struct stat st;
if (fstat(fd, &st) < 0) {
printf("find: cannot stat %s\n", path);
close(fd);
return;
}
if (strcmp(name, get_name(path)) == 0)
printf("%s\n", path);
if(st.type == T_DIR)
{
char buf[512], *p;
struct dirent de;
if (strlen(path) + 1 + DIRSIZ + 1 > sizeof(buf)) {
fprintf(2, "find: path too long\n");
return;
}
strcpy(buf, path);
p = buf + strlen(buf);
*p++ = '/';
while (read(fd, &de, sizeof(de)) == sizeof(de)) {
if (de.inum == 0)
continue;
if (strcmp(de.name, ".") == 0 || strcmp(de.name, "..") == 0)
continue;
memmove(p, de.name, DIRSIZ);
p[DIRSIZ] = 0;
find(buf, name);
}
}
close(fd);
}
int main(int argc, char *argv[]) {
if (argc != 3) {
printf("usage: find path name\n");
exit(0);
}
find(argv[1], argv[2]);
exit(0);
}
|
xargs(moderate)
将 stdin 的输入变成 args.
怎么说呢,a | b 这样执行的话,似乎并不会等待 a 执行完毕后再执行 b. 那么在开头一次性读入 stdin 就会失败。
手写一个类似于 getline 的东西就可以了。
uptime(easy)
调用 uptime system call 即可。
reg find(easy)
让 find 支持正则搜索名称。在 grep.c 中有一个简陋的正则实现。
把正则抄过来,然后 strcmp 改成 match 即可。
improve shell
- 从文件中执行命令时不输出
$ (moderate)
- 让 shell 支持 wait(easy)
- 支持用
; 分割的多命令(moderate)
- 支持 sub-shell
(...) (moderate)
- 支持 tab completion(easy)
- 存储历史命令(moderate)
这 optional challenge 也太多了,不做了(
LEC3
LEC2 是 C 语言复习,跳过了。
LEC3 涉及到一些操作系统的入门介绍,算是正式进入了 kernel 的学习吧。
Lab
本次的 Lab 是自己写一些 extra system calls.
总结一下写一个 system call 的流程:
- 在
syscall.h 中加入 #define SYS_xxx number
- 在
syscall.c 中加入 extern uint64 sys_xxx(void);,在 static uint64 (*syscalls[])(void) 数组中加上 [SYS_xxx] sys_xxx
- 在
sysproc.c 中加上 sys_xxx 的实现。
- 在
user.h 中加入对应的定义。
- 在
usys.pl 中加入 entry("xxx")
Systrace
可以设置每个 system call 的 tracing 状态,如果在追踪中则返回时输出一行日志。
trace 应当只对当前 process 及后代有效。
可以在 proc struct 中加一个 tracemask,fork 的时候把这个也拷贝上。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
|
const char* syscalls_names[] = {
[SYS_fork] "fork",
[SYS_exit] "exit",
[SYS_wait] "wait",
[SYS_pipe] "pipe",
[SYS_read] "read",
[SYS_kill] "kill",
[SYS_exec] "exec",
[SYS_fstat] "fstat",
[SYS_chdir] "chdir",
[SYS_dup] "dup",
[SYS_getpid] "getpid",
[SYS_sbrk] "sbrk",
[SYS_sleep] "sleep",
[SYS_uptime] "uptime",
[SYS_open] "open",
[SYS_write] "write",
[SYS_mknod] "mknod",
[SYS_unlink] "unlink",
[SYS_link] "link",
[SYS_mkdir] "mkdir",
[SYS_close] "close",
[SYS_trace] "trace",
[SYS_sysinfo] "sysinfo",
};
void syscall(void) {
int num;
struct proc *p = myproc();
num = p->trapframe->a7;
if (num > 0 && num < NELEM(syscalls) && syscalls[num]) {
p->trapframe->a0 = syscalls[num]();
if (p->tracemask & (1 << num)) {
printf("%d: syscall %s with args [%d %d %d %d %d %d]-> %d\n", p->pid,
syscalls_names[num], argraw(0), argraw(1), argraw(2), argraw(3),
argraw(4), argraw(5), p->trapframe->a0);
}
} else {
printf("%d %s: unknown sys call %d\n", p->pid, p->name, num);
p->trapframe->a0 = -1;
}
}
|
Sysinfo
收集信息到一个结构体中。
这次需要 kernel 中跨模块交流,在 defs.h 中添加函数的声明。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
|
// in proc.c
uint64 procnum(void) {
uint64 res = 0;
for (struct proc *p = proc; p < &proc[NPROC]; ++p) {
acquire(&p->lock);
res += p->state != UNUSED;
release(&p->lock);
}
return res;
}
// in kalloc.c
uint64 kcount_free(void) {
uint64 res = 0;
acquire(&kmem.lock);
for (struct run *p = kmem.freelist; p; p = p->next)
res += PGSIZE;
release(&kmem.lock);
return res;
}
// in sysproc.c
uint64
sys_sysinfo(void)
{
uint64 target;
if (argaddr(0, &target) < 0)
return -1;
struct sysinfo ret;
ret.freemem = kcount_free();
ret.nproc = procnum();
return copyout(myproc()->pagetable, target, (char *)&ret, sizeof(ret));
}
|
然后跑 sysinfotest 即可。
LEC4
讲 Page Table.
LEC5
讲了一下如何使用 gdb 进行调试。
Lab: page tables
Speed up system calls(easy)
可以通过在一片只读区域内在用户态和内核态之间共享数据来加速一些 system call.
在 allocproc 中照着 trampoline 一顿模仿即可。
需要修改的点包括:
-
proc.c
- allocproc
- freeproc
- proc_pagetable
- proc_freepagetable
-
proc.h
Print a page table(easy)
打印 Page Table.
需要修改的点:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
void vmprint_walk(pagetable_t pagetable, int depth){
if(depth == 3) return;
for(int i = 0; i < 512; ++i)
{
pte_t pte = pagetable[i];
if ((pte & PTE_V) == 0)
continue;
for (int i = 0; i < depth; ++i)
printf(".. ");
printf("..%d: pte %p pa %p\n", i, pte, PTE2PA(pte));
if ((pte & PTE_V) && (pte & (PTE_R | PTE_W | PTE_X)) == 0)
{
uint64 child = PTE2PA(pte);
vmprint_walk((pagetable_t)child, depth + 1);
}
}
}
// Print a page table
void vmprint(pagetable_t pagetable)
{
printf("page table %p\n", pagetable);
vmprint_walk(pagetable, 0);
}
|
Detecting which pages have been accessed(hard)
居然是个 hard,感到压迫、、、
需要实现一个 system call pgaccess(),报告哪些 pages 被访问过。
PTE_A 根据手册是 1L << 6。

需要修改的点:
调用 walk 然后简单判断一下就好了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
uint64 sys_pgaccess(void)
{
uint64 va, pres;
int num;
if (argaddr(0, &va) < 0)
return -1;
if (argint(1, &num) < 0)
return -1;
if (num > 64)
return -1;
if (argaddr(2, &pres) < 0)
return -1;
uint64 mask = 0;
for (int i = 0; i < num; ++i)
{
pte_t *pte = walk(myproc()->pagetable, va, 0);
if (*pte & PTE_A)
{
mask |= 1 << i;
*pte &= ~PTE_A; // clear access bit
}
va += PGSIZE;
}
return copyout(myproc()->pagetable, pres, (char*)&mask, sizeof(mask));
}
|
似乎算不上 hard?
LEC6
介绍了一下处理 traps 的方法。
终于知道 trampoline 是干啥用的了。trampoline map 了一片用于处理中断的指令,用于保存状态然后跳入 kernel 进行处理。
LEC7
介绍了 Page Fault,结合之前的 Page Tables 开始拓展各种炫酷的优化方法了。
- Lazy Allocation
- Copy On Write(COW)
- Demand Paging
- ……
Lab: traps
这个 Lab 跟 LEC7 暂且没啥关系。
RISC-V assembly(easy)
没学过汇编,糟糕力。
勉强看了一会,暂且跳过。还好不是要写的玩意。
Backtrace(moderate)
写一个 backtrace 函数,输出调用链。
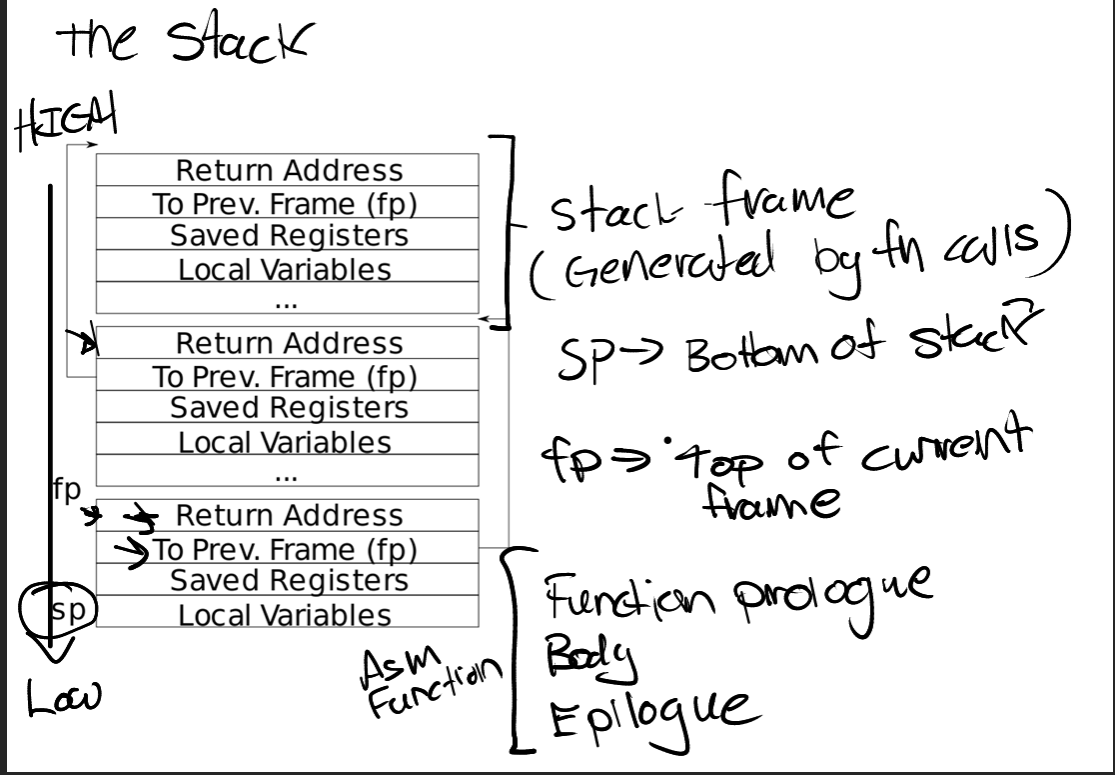
一个个 Stack Frame 跳上去,hint 热心给出了获取当前 frame pointer 地址的函数。
stack frame 的顶部有两个值:Return Address 和 fp.
Stack 似乎总是一个 Page,用这个方式可以及时终止。
backtrace 输出的就是 ra,而每次用 fp 往上跳就行了。
1
2
3
4
5
6
7
8
9
10
11
12
13
|
void backtrace()
{
uint64 fp = r_fp();
uint64 top = PGROUNDUP(fp);
uint64 bot = PGROUNDDOWN(fp);
uint64 ra;
while (fp > bot && fp < top)
{
ra = *((uint64 *)(fp)-1);
printf("%p\n", ra);
fp = *((uint64 *)(fp)-2);
}
}
|
Alarm(hard)
加一个 system call,让进程调用后,每隔 n tick 就调用其指定的函数。类似于加了一个周期时钟。
太酷力,而且感觉确实很高难度啊。
花了一小时搓完了。
更改的地方:
- proc.c
- proc.h
- syscall.c
- syscall.h
- sysproc.c
- trap.c
- user.h
- usys.pl
首先需要两个 system calls:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
uint64 sys_sigalarm(void)
{
int interval;
void (*handler)();
if (argint(0, &interval) < 0)
return -1;
if (argaddr(1, (uint64 *)&handler) < 0)
return -1;
if (interval < 0)
return -1;
struct proc* p = myproc();
p->interval = interval;
p->handler = handler;
p->passed_tick = 0;
return 0;
}
uint64 sys_sigreturn(void)
{
struct proc* p = myproc();
p->handling = 0;
memmove(p->trapframe, p->alarmframe, sizeof(struct trapframe));
kfree(p->alarmframe);
return 0;
}
|
当然,还需要魔改一下 struct proc 记录额外的信息:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
|
// Per-process state
struct proc {
struct spinlock lock;
// p->lock must be held when using these:
enum procstate state; // Process state
void *chan; // If non-zero, sleeping on chan
int killed; // If non-zero, have been killed
int xstate; // Exit status to be returned to parent's wait
int pid; // Process ID
// wait_lock must be held when using this:
struct proc *parent; // Parent process
// these are private to the process, so p->lock need not be held.
uint64 kstack; // Virtual address of kernel stack
uint64 sz; // Size of process memory (bytes)
pagetable_t pagetable; // User page table
struct trapframe *trapframe; // Data page for trampoline.S
struct context context; // swtch() here to run process
struct file *ofile[NOFILE]; // Open files
struct inode *cwd; // Current directory
char name[16]; // Process name (debugging)
int interval; // Alarm Interval
int passed_tick; // Ticks passed since last alarm
int handling; // If the handler is running
void (*handler)(); // Alarm handler
struct trampframe *alarmframe; // Data page for alarm trap
};
|
然后修改 usertrap.
主要的思路是先保存现场,然后将 Program Counter 直接设置到我们要执行的 handler 那里,这样 trapret 之后就马上会执行我们的函数。
保存现场的话,其实既然是 trap,那本身就已经把状态存在 trapframe 里了,我干脆直接把 trapframe 拷贝一份到 alarmframe 里面。
这里内存是动态分配的,如果使用频繁也可以像 trapframe 那样在 alloc proc 的时候就分配。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
// give up the CPU if this is a timer interrupt.
if(which_dev == 2)
{
if(p->interval > 0 && p->handling == 0)
{
++p->passed_tick;
if (p->passed_tick >= p->interval)
{
// save the current status of the process
// then execute the alarm handler
if((p->alarmframe = (struct trampframe *)kalloc()) == 0)
panic("allocate alarmframe failed.");
memmove(p->alarmframe, p->trapframe, sizeof(struct trapframe));
p->trapframe->epc = (uint64)p->handler;
p->handling = 1;
p->passed_tick = 0;
}
}
yield();
}
|
按照设计,handler 最后会调用 sigreturn 的 syscall,而 syscall 也是通过 trap 实现的,返回时会使用 trapframe 的值。那我们在 sigreturn 中把 trapframe 改写就可以了。
还要注意到,a0 寄存器是会被 syscall 的返回值覆盖的,那我们可以在 syscall 函数里特判一下……
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
void
syscall(void)
{
int num;
struct proc *p = myproc();
num = p->trapframe->a7;
if (num > 0 && num < NELEM(syscalls) && syscalls[num])
{
uint64 ret = syscalls[num]();
if (num != SYS_sigreturn)
p->trapframe->a0 = ret;
}
else
{
printf("%d %s: unknown sys call %d\n",
p->pid, p->name, num);
p->trapframe->a0 = -1;
}
}
|
这样所有寄存器的状态都保存完好啦!
虽然不知道靠不靠谱,但至少 alarmtest 和 usertests 都跑过了,那就这样吧。
LEC9
讲了 Device Interruption.
现在似乎 Lab 总是落后 Lecture 进度一节啊……
Lab: Copy-on-Write Fork
简称 COW.
COW fork 可以让 fork 出的 process 只在修改内存的时候才实际进行拷贝,也就是 process 和它的所有 sub-processes 共享未更改的内存。
感觉和可持久化数据结构的 trick 类似。
当然,如果 parent process 要修改内存,也要拷贝一份。
那么可以给 memory 计一个 ref count,如果当前 memory 被一个进程独占,那么可以直接修改。否则就拷贝一份, 并将原先的 ref count 减一。
利用 Page Fault 作为入口。每次 fork 之后,将要共享的内存标记为 read-only,这样要写的时候触发 Page Fault,然后再 Copy.
当然,触发 Page Fault 还是有额外开销的。最朴素的实现就是每次读哪里就把那个 Page 复制了,如果考虑 Page Fault 开销的话可以考虑一次写就多复制一点。
ref count 记录在哪里也是个问题。还需要区分是 COW fork 造出来的 read-only 还是货真价实的 read-only. 可以利用 PTE 的 reserved bit 来标记 COW read-only.
- 原本想 fork 的时候干脆复制 pagetable 根,然后按可持久化树那样做 path update,不过似乎没法在节点上记录状态,pagetable 大概也不大吧,那就直接 duplicate 一份算了。
- 指向的 Page 不变,可以给每个 Page 都记录状态。这大概需要一个 map?4kb 一个 Page 的话,1M 就需要 256 个数,128M 就需要 32768 个数,每个数都是 8 bytes 的话,将占掉 262144 bytes 的内存,也就是——256kb. 好吧,其实开个数组还是可以接受的。而且其实 数的范围可以小一点。
- 那么 free 的时候,可以只让 ref count 减一。直到 ref count 为零的时候才真正 free.
其实如果可能的话,为什么 page table 的结构不能更复杂一些呢?可以给 page table 开一个辅助树,复刻 page table 的结构,只不过节点上额外存放一些 metadata. 这样拓展起来就方便多了。
至于 ref 数组怎么开,最简单的方法就是——直接开成全局变量。但这样大小是固定的。我们可以在初始化的时候计算出有多少 free memory,然后计算出 free page 的总数,然后动态开数组。
问题在于 ref 数组一个 page 是装不下的。受到了 page table 的启发,我们可以搓一个类似于 page table 的数据结构,第一层作为索引,第二层作为真正的 ref array. 这样对于我们的 free memory 大概是够用的。直接开出来就可以了。
初始化 ref 数组要分配 pages,但 kalloc kfree 又依赖 ref count. 那么写一个只在初始化时使用的 no ref 版本,初始化完成后把这些 page 的 ref count 记上。其实不计似乎也无所谓。总之一番折腾终于整好了 ref 数组。
接下来就是处理 Page Fault 了。scause 为 15,读取 stval 也就是对应的地址。
检测 PTE 上的标记,然后判断 COW 就可以了。
还需要在 kernel 的 copyout 函数里也处理一下,因为这里写 user memory 的时候并不在 user mode,不会进入 usertrap.
好不容易写完了,结果跑 usertests 跑出内存泄漏了?少了一个 page,草。而且非常稳定地少一个 page,太抽象了。更抽象的是这还是跑所有 tests 才会出的 bug,部分测试是测不出来的。
经过我的艰苦排查,发现 execout 和 mem 一起测就会漏一个 page. 而且是 execout -> mem 的顺序才会。
猜测是进程 run out of memory 会触发什么奇怪的 bug.
经过检查,发现是这个问题:execout 耗尽内存后再写 COW 内存,ref count 自减后 kalloc 失败退出,pa 不变,导致后续 ref count 不准。
要在 copy 成功之后再减少 ref count,过程中得一直持有锁。考虑以下情况:
-
ref count > 1,进行 copy,内存不足 kalloc 失败。
- 这个情况发生时,ref count 不能减。也就是必须 copy 成功后再减 ref count.
- 考虑 ref count = 2 时,一个进程进入 copy 分支,先减了 ref count. 另一个进程进入 ref count = 1 的覆写分支,结果 copy 分支 kalloc 失败,ref count 回滚到 2 已经是为时已晚。
-
ref count > 1,进行 copy,同时另一个进程也进入了 ref count > 1 的分支进行 copy.
- 如果是 acquire-> 读 ref count 进入分支->release->copy->acquire->decrement->release 的话,这种情况可能在 ref count = 2 时令两个进程同时进入 copy 分支,导致 ref count -> 0 异常
-
ref count = 2 进行 copy,另一个进程进入 ref count = 1 的分支进行覆写。如果加锁不全可能导致 copy 到的数据已经被覆写。
真是不容易啊……听 Lecture 的时候感觉他们应该做了一个前面的 Lazy Allocation Lab 练手才对,为何 schedule 上没有呢。
各方面来说实现得都很丑陋( 懒得 refine 了。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
|
// Copy page table, but do not copy physical memory
// Set PTE_C and PTE_W
int
uvmcopy_fork(pagetable_t old, pagetable_t new, uint64 sz)
{
pte_t *pte;
uint64 pa, i;
uint flags;
for(i = 0; i < sz; i += PGSIZE){
if((pte = walk(old, i, 0)) == 0)
panic("uvmcopy: pte should exist");
if((*pte & PTE_V) == 0)
panic("uvmcopy: page not present");
if(*pte & PTE_W)
{
*pte |= PTE_C;
*pte &= ~PTE_W;
}
pa = PTE2PA(*pte);
flags = PTE_FLAGS(*pte);
ref_acquire();
ref_incre(pa);
ref_release();
if(mappages(new, i, PGSIZE, (uint64)pa, flags) != 0){
goto err;
}
}
return 0;
err:
uvmunmap(new, 0, i / PGSIZE, 1);
return -1;
}
int copy_on_write(pte_t *pte)
{
uint64 pa = PTE2PA(*pte);
ref_acquire();
uint64 ref = ref_get(pa);
if (ref > 1)
{
void *mem = kalloc();
if (!mem)
{
printf("usertrap(): out of memory\n");
ref_release();
return -1;
}
memmove(mem, (const void *)pa, PGSIZE);
int flags = PTE_FLAGS(*pte);
flags &= (~PTE_C);
flags |= PTE_W;
*pte = PA2PTE(mem) | flags;
ref_decre(pa);
ref_release();
}
else if (ref == 1)
{
// ref == 1, set as normal
*pte |= PTE_W;
*pte &= ~PTE_C;
ref_release();
}
else
{
printf("COW ref count error! ref = %d\n", ref);
ref_release();
return -1;
}
return 0;
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
#define RCAP (PGSIZE / sizeof(uint64))
uint64 ref_start, *refs;
struct spinlock ref_lock;
void ref_acquire(void) { acquire(&ref_lock); }
void ref_release(void) { release(&ref_lock); }
// return the ref count of the page that pa belongs to
uint64 ref_get(uint64 pa)
{
if(pa < ref_start || pa >= PHYSTOP)
panic("ref_get: invalid pa");
uint64 pgnum = (pa - ref_start) / PGSIZE;
return *((uint64 *)refs[pgnum / RCAP] + (pgnum % RCAP));
}
uint64 ref_incre(uint64 pa)
{
if(pa < ref_start || pa >= PHYSTOP)
panic("ref_get: invalid pa");
uint64 pgnum = (pa - ref_start) / PGSIZE;
// printf("incre %d to %d\n", pgnum, 1 + (*((uint64 *)refs[pgnum / RCAP] + (pgnum % RCAP))));
return ++(*((uint64 *)refs[pgnum / RCAP] + (pgnum % RCAP)));
}
uint64 ref_decre(uint64 pa)
{
if(pa < ref_start || pa >= PHYSTOP)
panic("ref_get: invalid pa");
uint64 pgnum = (pa - ref_start) / PGSIZE;
// printf("decre %d to %d\n", pgnum, (*((uint64 *)refs[pgnum / RCAP] + (pgnum % RCAP))) - 1);
return --(*((uint64 *)refs[pgnum / RCAP] + (pgnum % RCAP)));
}
void refinit()
{
refs = (uint64*)kalloc_noref();
ref_start = PGROUNDUP((uint64)end);
memset((void*)refs, 0, PGSIZE);
uint64 need = (((PHYSTOP - ref_start) / PGSIZE) + (RCAP - 1)) / RCAP;
for(int i = 0; i < need; ++i)
{
refs[i] = (uint64)kalloc_noref();
memset((void*)refs[i], 0, PGSIZE);
}
ref_incre((uint64)refs);
for (int i = 0; i < need; ++i)
ref_incre(refs[i]);
}
|